
Fault-tolerant design refers to designing systems that continue operating properly even when faults or failures occur.
Rather than avoiding failures, fault-tolerant systems are designed to cope with faults and gracefully degrade functionality if necessary.
By anticipating potential points of failure and instituting redundancy, fault-tolerant systems aim to minimize disruption and data loss.
Fault tolerance is especially crucial for mission-critical applications where downtime has high costs.
Understanding fault-tolerant principles and architecture patterns enables the creation of resilient systems that provide reliably uninterrupted services.
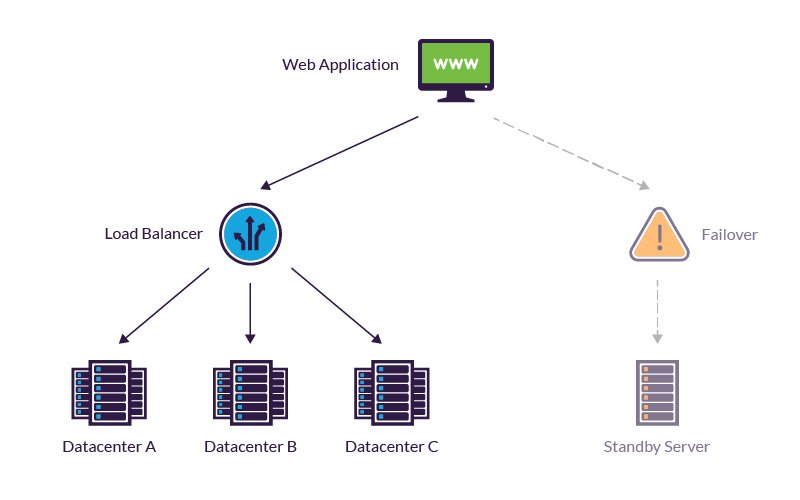
Need for Fault Tolerance
There are several key reasons fault-tolerant systems are important:
- Prevent complete system failure when faults inevitably occur.
- Maximize service uptime and availability for critical applications.
- Ability to maintain functionality without delays for repairs.
- Avoid the high costs of system disruptions or shutdowns.
- Maintain data integrity by preventing corruption or loss.
- Ensure continuity of operations without human intervention.
By planning for failures, system reliability, and uptime can be improved cost-effectively.
Fault Tolerance Techniques
Common techniques used to build fault-tolerant systems include:
- Redundancy – Critical components are replicated so there are backups if one fails.
- Monitoring – Early fault detection via self-monitoring and diagnostics.
- Failover – Automatically switching to standby components in the event of a failure.
- Isolation – Isolate failed parts and prevent issues from propagating.
- Transactions – Make operations atomic and reversible to maintain data integrity.
- Replication – Duplicate and synchronize critical data across multiple systems.
- Load Balancing – Distribute workload across components to avoid single points of failure.
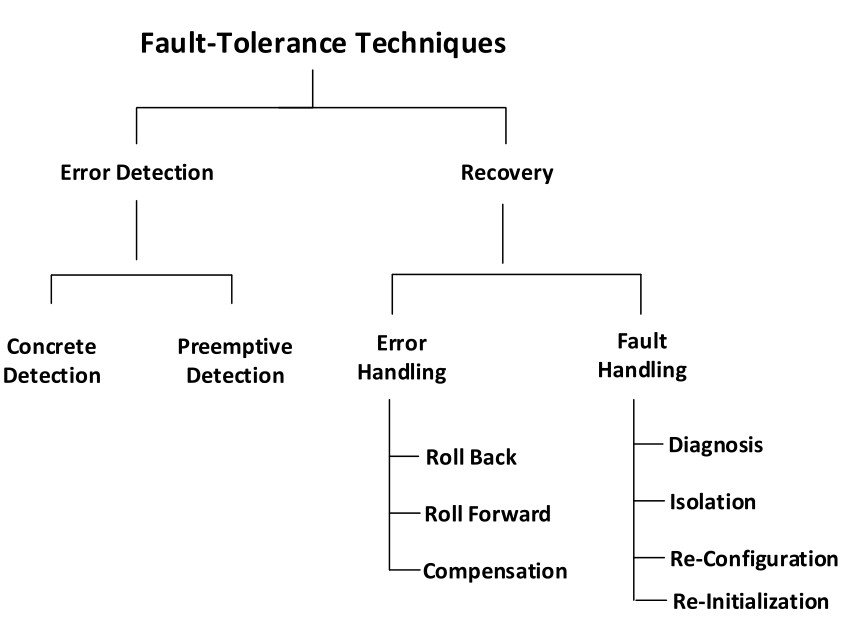
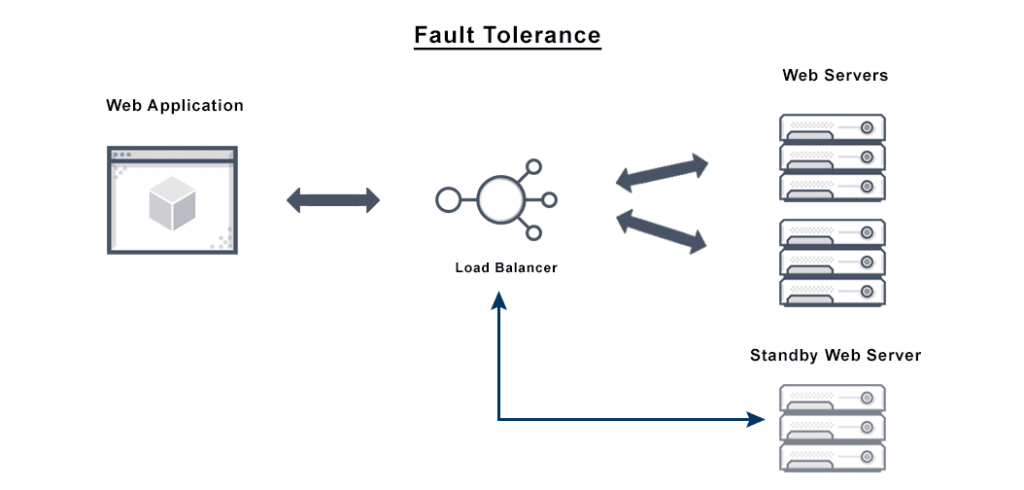
Fault Tolerant Architecture
A typical fault-tolerant architecture pattern contains:
- Redundant Components – Independent backup components like redundant power supplies, servers, and network links for no single point of failure.
- Error Detection – Self-monitoring and reporting to detect failures and trigger recovery.
- Failover Mechanism – Component for automatically switching to standby path or system upon failure detection.
- Replication – Critical data is replicated between systems to avoid loss if a system fails.
- Isolation – Faults are contained by shutting down failed parts to avoid contaminating systems still running.
Examples of Fault Tolerance
Some common examples of exploiting fault tolerance principles:
- RAID – Disk arrays with redundancy that can survive individual drive failures.
- Cluster Computing – Servers replicate jobs transparently across nodes. Failure of a node does not halt service.
- Hot Swappable Components – Replace failed components without interrupting running systems.
- Watchdog Timers – Circuit monitors system health and reboots if issues are detected.
- Transaction Processing – Atomic commits and rollbacks maintain data integrity.
- High Availability – Auto-failover keeps services continuously available despite failures.
Challenges of Fault-Tolerant Design
Some considerations when implementing fault-tolerant systems:
- Complexity – Added redundancy incurs development, testing, and maintenance costs.
- Expense – Fault-tolerant components are more expensive than standard counterparts.
- Latency – Monitoring, failover, and replication introduce delays during normal operation.
- Scaling difficulty – At large scales, uniformly high fault tolerance becomes extremely complex.
- Diminishing returns – Each increment of added redundancy delivers less resilience benefit.
Fault Tolerance in Distributed Systems
In large-scale distributed systems like cloud platforms, fault tolerance mechanisms take on increased importance. Key principles used include:
- Decentralization – Avoid single centralized points of failure. Distribute components.
- Redundancy – Replicate across geographic regions and availability zones.
- Auto-scaling – Automatically launch new instances if existing ones fail.
- Microservices – Independent services can fail without taking the entire system down.
- Load balancing – Route across redundant components to circumvent disrupted paths.
Conclusion
By anticipating potential failures and instituting redundant components and recovery methods, fault-tolerant systems aim to provide uninterrupted services and data integrity.
While complex and costly to implement fully, fault tolerance is crucial for mission-critical applications where even minor disruptions incur substantial expense.
A layered approach allows targeting the most important parts of a system for fault tolerance.
As our world grows increasingly dependent on software systems, fault tolerance principles will continue gaining importance in engineering highly reliable solutions.
Frequently Asked Questions (FAQ)
Ques 1: What is graceful degradation in fault-tolerant systems?
Ans: Graceful degradation is the ability of a system to maintain limited functionality rather than completely shutting down when some components fail.
By isolating faults and allocating remaining resources effectively, the system can continue providing partial services during failure scenarios.
Q2: What are the differences between fault tolerance, high availability, and reliability?
Ans: Fault tolerance maintains system operation through redundancy. High availability ensures a system provides continuous service through features like automatic failover.
Reliability refers to the probability a system will function properly for a specified period. The terms overlap in improving system uptime.
Q3: What are some key elements of a fault-tolerant architecture?
Ans: Key elements include redundancy of critical components, monitoring & self-diagnostics, failover mechanisms, result comparison, transaction processing, master-slave configurations, load balancing, checkpointing, data replication, and isolation of failed modules.
Q4: What is N-modular redundancy?
Ans: N-modular redundancy implements multiple identical redundancy modules working in parallel. Their results are compared through a voting mechanism.
If one module provides a differing result, it is isolated while the matched result of the other modules is used. This continues service through any single module failure.
Q5: What is the primary drawback of extensive fault tolerance?
Ans: The primary drawback is increased cost and complexity from redundant components, monitoring systems, and backup infrastructure.
At large scale, uniformly high fault tolerance becomes prohibitively complex and expensive. A cost-benefit analysis helps target critical system areas to focus on fault tolerance mechanisms.






